
Understanding Stable Diffusion
The Magic Behind AI image generation

You’ve likely seen them – photos reimagined as scenes straight out of a Studio Ghibli film, brimming with soft colors and whimsical detail. This “Ghiblification” trend sweeping social media isn't just clever artistry; it’s powered by a fascinating piece of technology called Stable Diffusion, and it represents a huge leap forward in the world of AI image generation. But what is Stable Diffusion, and how does it turn your snapshots into animated masterpieces?

For years, creating images with AI felt imperfect. Results were often blurry, distorted, or simply lacked artistic coherence. Stable Diffusion changed that. It’s not about an AI “painting” from scratch; instead, imagine a process of intelligent refinement. Think of it like this: you give the AI a starting point – your photo – and then guide it with text prompts, telling it what kind of image you want to create.
But how does it actually work? The core idea behind Stable Diffusion is surprisingly elegant. It operates on something called “diffusion models.” Traditionally, creating an image starts with pure noise—think static on a television screen. A diffusion model learns to reverse this process. It’s trained on massive datasets of images and gradually learns how to remove the noise, step-by-step, revealing recognizable patterns and details.
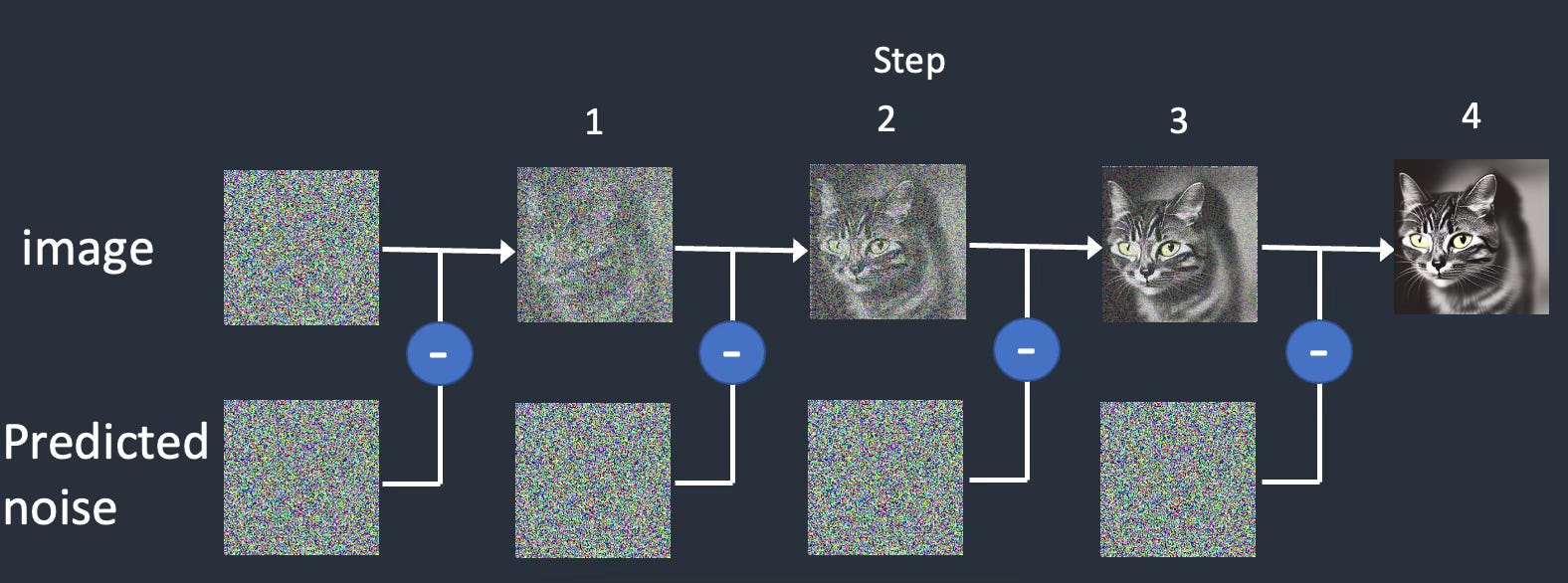
Stable Diffusion takes this concept further by working in a “latent space.” This is where things get slightly less intuitive, but bear with me. Instead of directly manipulating pixels (the tiny dots that make up an image), Stable Diffusion compresses images into a more manageable representation – essentially a simplified code. It then performs the noise removal process within this compressed space, making it much faster and requiring less computing power. This is why you can run Stable Diffusion on relatively accessible hardware, unlike some earlier AI image generators.
Once the refined image exists in the latent space, it’s “decoded” back into a full-resolution picture that we can see. The text prompt you provide acts as a guiding force throughout this entire process. It tells the model what to create while removing the noise – "in the style of Studio Ghibli," "a portrait with soft lighting," or even incredibly specific requests like “a cat wearing a tiny hat, painted by Van Gogh.”
What makes Stable Diffusion particularly powerful is its open-source nature. Unlike many AI models locked behind corporate walls, Stable Diffusion’s code is publicly available. This has fostered a vibrant community of developers and artists who are constantly refining the model, creating new tools, and expanding its capabilities. It's this collaborative spirit that has fueled the rapid innovation we see in AI image generation today.
The recent GPT-4o update from OpenAI (the creators of ChatGPT) leverages technology similar to Stable Diffusion, allowing users to easily create these Ghibli-inspired images directly within the chatbot interface. OpenAI is even taking steps to address concerns about mimicking living artists by adding safeguards that prevent direct style replication while still permitting broader stylistic influences like “studio styles.”
However, this ease of creation also raises important questions about copyright and artistic ownership. You can refer to my previous post on this topic.
The “Ghiblification” trend isn’t just a fleeting internet moment; it's a glimpse into a future where AI empowers creativity in new and exciting ways. Stable Diffusion has democratized image generation, putting the power of artistic expression into the hands of anyone with an idea and a computer. As the technology continues to evolve, it will be fascinating to see how artists and creators embrace these tools and redefine what’s possible in the world of visual media.
